I noticed at a recent Meetup in New York – http://youtu.be/-Z-NuSklwWU?t=39m38s – that the performance of the AngularJS docs app was questioned and quite rightly so. Loading up the docs app was a complete dog!
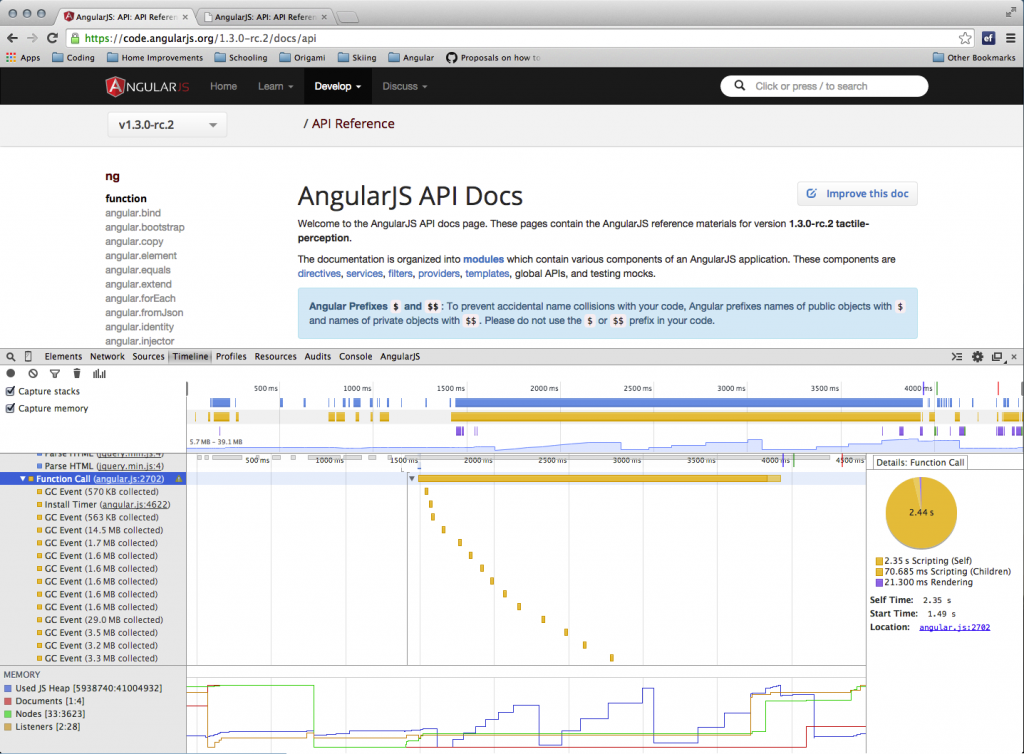
As you can see from this Chrome timeline the page is taking over 4 secs (on a fairly powerful laptop with fast broadband connection) to complete loading and rendering.
The mystery of the blocking script
What is going on here? Well the actual loading of the various files is not too bad (though it could be better). Most of the files are loaded within 1500ms. But then there is this mysterious block of script evaluation happening from 1500ms to around 4000ms. What is worse this script is blocking the whole browser. So the user experience is terrible. On a phone you might have to wait ten or more seconds, looking at a pretty blank page, before you can start browsing the docs.
In the video Brad and Misko suggest that the problem is with a Google Code Prettify plugin that we use to syntax highlight our inline code examples. It turns out that while this is a big old file the real problem is elsewhere. Notice how the memory during this blocking script goes up and up with a number of garbage collection cycles throughout? This is due to a memory intensive process.
Houston… we have a problem with the Lunr module
A quick look at a profile of the site loading show us that the main offenders are found in the lunr.js file.
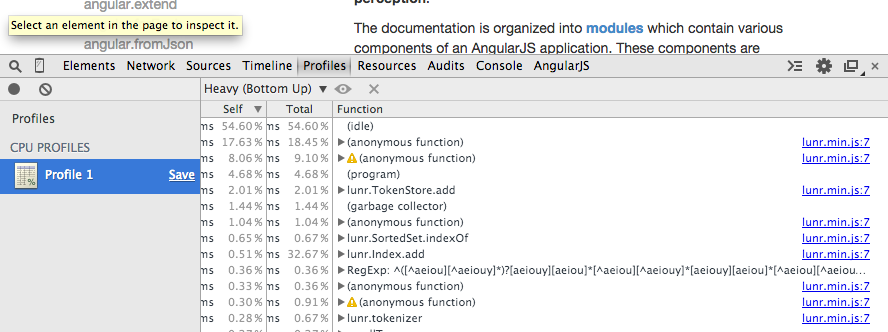
Lunr is the full text search engine that we run inside our app to provide you with the excellent instant search to all the Angular docs (API, guides, tutorials, etc). Unfortunately, we are creating the search index in the browser at the application bootstrap, which is blocking the rest of the application from running and stopping the page from rendering.
I looked at various different options to fix this. Initially I thought, “Let’s just generate this index on the server and download it”. Sadly the generated index is numerous Mb in size so this is not acceptable (especially if you are on your 3G connection)! I also looked around to see if there were alternative search engines we could use. I didn’t find anything that looked like it would be more performant that Lunr.
Getting async with Web Workers
So if this was no go and we must generate the index in the browser we needed a way to do it without blocking the rendering of the page. The obvious answer is to do it in a Web Worker. These clever little friends are scripts that run on their own thread in the browser (so not blocking the main rendering thread), to which we can pass messages back and forth. So we simply create a new worker when the application bootstraps and leave it to generate the index.
Since the messages that can be passed between the main application and the worker must be serialized it was not possible to pass the entire index back to the application. So instead we keep the index in the worker and use messages to send queries to the index and messages to get the results back.
This all has to happen asynchronously but thats OK because AngularJS loves async and provides an implementation of the beautiful Q library, in the form $q service.
The code for the docsSearch service to set up and query the index looks like this:
// This version of the service builds the index in a WebWorker,
// which does not block rendering and other browser activities.
// It should only be used where the browser does support WebWorkers
function webWorkerSearchFactory($q, $rootScope, NG_PAGES) {
console.log('Using WebWorker Search Index')
var searchIndex = $q.defer();
var results;
var worker = new Worker('js/search-worker.js');
// The worker will send us a message in two situations:
// - when the index has been built, ready to run a query
// - when it has completed a search query and the results are available
worker.onmessage = function(oEvent) {
$rootScope.$apply(function() {
switch(oEvent.data.e) {
case 'index-ready':
searchIndex.resolve();
break;
case 'query-ready':
var pages = oEvent.data.d.map(function(path) {
return NG_PAGES[path];
});
results.resolve(pages);
break;
}
});
};
// The actual service is a function that takes a query string and
// returns a promise to the search results
return function(q) {
// We only run the query once the index is ready
return searchIndex.promise.then(function() {
results = $q.defer();
worker.postMessage({ q: q });
return results.promise;
});
};
}
webWorkerSearchFactory.$inject = ['$q', '$rootScope', 'NG_PAGES'];
You can see that since we are interacting with an async process outside of Angular we need to create our own deferred object for the index and also use $apply to trigger Angular’s digest when things happen.
The service itself is a function which takes a query string (q). It returns a promise to the results, which will be resolved when both the index has been generated and the query results have been built. Notice also that the query is not even sent to the Web Worker thread until the promise to the built index has been resolved. This makes the whole thing very robust, since you don’t need to worry about making queries before the index is ready. They will just get queued up and your promises will be resolved when everything is ready.
In a controller we can simply use a .then handler to assign the results to a property on the scope:
docsSearch(q).then(function(hits) {
$scope.results = hits;
});
The effect of this is that we now have completely removed the blocking JavaScript from the main thread, meaning that our application now loads and renders much faster.

See now that the same block of script is there but now the solid darker rectangle is much smaller (only 0.5ms). This is the synchronous blocking bit of the script. The lighter paler block is the asynchronous children, which refers to our web worker. Interesting by moving this into a new thread it also runs faster as well, so a win all round!
But what about Internet Explorer?
There is always the question of browser support. Luckily most browsers do support Web Workers. The outstanding problems are the older Android browsers and of course Internet Explorer 8 and 9. So we have to put in place a fallback for these guys. I considered using a Web Worker shim but actually that would just add even more code for the browser to download and run. Instead I used the little understood service provider pattern to be able to dynamically offer a different implementation of the docsSearch service depending upon the browser capabilities.
.provider('docsSearch', function() {
return {
$get: window.Worker ? webWorkerSearchFactory : localSearchFactory
};
})
The webWorkerSearchFactory, which we saw above, is provided if the browser supports Web Workers. Otherwise the localSearchFactory is provided instead.
This local search implementation is basically what we had in place in the non-performant version of the docs app but with a small user experience improvement. We still have to block the browser at some point to generate the index but rather than doing it immediately at application bootstrap we delay the work for 500ms, which gives the browser time to at least complete the initial rendering of the page. This gives the user something to look at while the browser locks up for a couple of seconds as it generates the index.
// This version of the service builds the index in the current thread,
// which blocks rendering and other browser activities.
// It should only be used where the browser does not support WebWorkers
function localSearchFactory($http, $timeout, NG_PAGES) {
console.log('Using Local Search Index');
// Create the lunr index
var index = lunr(function() {
this.ref('path');
this.field('titleWords', {boost: 50});
this.field('members', { boost: 40});
this.field('keywords', { boost : 20 });
});
// Delay building the index by loading the data asynchronously
var indexReadyPromise = $http.get('js/search-data.json').then(function(response) {
var searchData = response.data;
// Delay building the index for 500ms to allow the page to render
return $timeout(function() {
// load the page data into the index
angular.forEach(searchData, function(page) {
index.add(page);
});
}, 500);
});
// The actual service is a function that takes a query string and
// returns a promise to the search results
// (In this case we just resolve the promise immediately as it is not
// inherently an async process)
return function(q) {
return indexReadyPromise.then(function() {
var hits = index.search(q);
var results = [];
angular.forEach(hits, function(hit) {
results.push(NG_PAGES[hit.ref]);
});
return results;
});
};
}
localSearchFactory.$inject = ['$http', '$timeout', 'NG_PAGES'];
We could, of course, go further with this and chunk up the index building into smaller blocks that are spaced out to prevent a long period of blocking but since the number of browsers that this affects is growing smaller by the day it didn’t make sense to put more development time into this.
To cache or not to cache?
Some of you might be wondering why we are not then caching the generated index into the LocalStorage. This is certainly an option but it raises additional questions, such as:
How and when we should invalidate old cached indexes? We generally release a new version of AngularJS once a week; so it is likely that the cache will need to be invalidated weekly; also people may want to look at different versions of the docs, should we cache more than one version and how do we decide which ones to keep.
Also, LocalStorage has very variable and limited capacity. One has to put in place code to cope with storage running out. The indexes are rather large so this could happen quite often.
On mobile we probably don’t want to be caching multiple large indexes anyway since storage is more of a premium in such devices.
Given the speed and user experience improvements achieved simply by moving the index generation to a new thread it was felt that this was a good enough solution for now.
Further Performance Improvements
In addition to this refactoring of the search index, we have also removed dead code, refactored other bits to lower the amount of data that must be transfered and minified much of the rest of the JavaScript. Our top man Jeff has also tweaked the server so we should be getting many more files zipped up when downloading now too.
If you have any other suggestions feel free to comment or even better put together a Pull Request to the repository with further improvements!
 I used to be quite happy with fossil fuels from GWT Co: They were so cheap, reliable and freely available.
I used to be quite happy with fossil fuels from GWT Co: They were so cheap, reliable and freely available. So I have switched energy companies to use one of those cool new green tariffs from ngGreen. Now a large proportion of my energy comes from renewable sources, such as Wind and Solar (and possible nuclear fission!).
So I have switched energy companies to use one of those cool new green tariffs from ngGreen. Now a large proportion of my energy comes from renewable sources, such as Wind and Solar (and possible nuclear fission!). Recently, I heard that there is this new renewable energy source, based on nuclear fusion. Apparently the Tokamak facility managed to achieve 30 seconds of sustained fusion. In the future there is no doubt that we will all be relying on this cool new technology to provide all our energy needs.
Recently, I heard that there is this new renewable energy source, based on nuclear fusion. Apparently the Tokamak facility managed to achieve 30 seconds of sustained fusion. In the future there is no doubt that we will all be relying on this cool new technology to provide all our energy needs.

